
Aug 21, 2022 By Team YoungWonks *
Introduction
As someone who is regularly fascinated by the real-world potential of data mining, data science and machine learning, I find myself desiring very specific datasets more often than I’d like to admit (especially E-commerce websites like Amazon and other social media websites) and I’m not one to shy away from making this known. Unsurprisingly, I was recently contacted by a former colleague, hoping they could get a dataset on blue-collar jobs to determine trends and inform a study they were a part of. By nature, this was one I knew I’d have to scrape for. And scrape I did!
Ideally, contacting the owners of target websites will yield the most accurate data, in addition to data from the past. Easier said than done however for more reasons than one, scraping has become the de facto way of obtaining data for studies focusing on niches. A lot of webpage owners are aware of this and provide convenient APIs to help with data procurement.
Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favourite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree.
The titular Python module is what we’ll be using to scrape and parse the target website. Python is an extremely powerful language, partly due to the plethora of modules available to import and use. We begin by installing and using the Python module. While this module is powerful in its own right, when used in conjunction with various other modules, any website can be scraped irrespective of whether the website loads data dynamically, or if it requires us to login. For our purposes here, we will restrict ourselves to a dataset from a static website on the aforementioned topic: blue-collar jobs.
Disclaimer: Although implicitly legal, web scraping could potentially harm the website being scraped. Moreover, the website’s owner’s stance on scraping is mutable. I neither endorse, nor condone scraping irresponsibly. I always try my best to ensure I don’t make more requests than required to the target website.
The titular Python module is surprisingly beginner-friendly and is what we’ll be using to scrape and parse the target website. Python is an extremely powerful language, partly due to the plethora of modules available to import and use. We begin by installing and using the Python module beautifulsoup4. While this module is powerful in its own right, when used in conjunction with various other modules, any website can be scraped irrespective of whether the website loads data dynamically, or if it requires us to login. For our purposes here, we will restrict ourselves to a dataset from a static website on the aforementioned topic: blue-collar jobs.
Disclaimer: Although implicitly legal, web scraping could potentially harm the webpage being scraped. Moreover, the website’s owner’s stance on scraping is mutable. I neither endorse, nor condone scraping irresponsibly. I always try my best to ensure I don’t make more requests than required to the target website.
Scraping
Dependencies
Python3 The requests library, BeautifulSoup library, sys, time, selenium and pandas libraries Familiarity with Python and HTML syntax, alongside pandas (JavaScript and CSS may be needed in some cases)
Installation
Terminal:
pip install html5lib
pip install beautifulsoup4
If you are using Google Colab like I am:
!apt-get update
!pip install selenium
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
Please refer to the second post in the references (final section) for more information.
Implementation
Step I - Importing the Required Modules:
We start by importing all the required modules. The tail end of the following code block is for running Selenium on Colab. Please note that Selenium will be required to deal with websites that load in data dynamically (eg. websites that load in more data as the user keeps scrolling; dealt with in step vi).

Step II (Testing) - Obtaining the Webpage’s SRC:
The target website uses CloudFlare, which by default blocks any request we send, probably to ward off and protect from unwanted requests. A simple workaround is to modify the header and change the user-agent to a known browser (instead of the default header: python-requests/2.23.0).
We then create a BeautifulSoup object using the webpage’s content. Upon careful inspection of the source HTML content and various HTML tags, I realised that the website’s developer did an excellent job of organising all the divs and the class we’re after is ‘JobItem’, as should be the case with any web development project. I would recommend using your favourite browser’s inspect mode to perform any such exploration as they let us highlight elements. Please note that Safari does not have the web inspector enabled by default.

Step III (Testing) - Identifying and Extracting the Specifics:
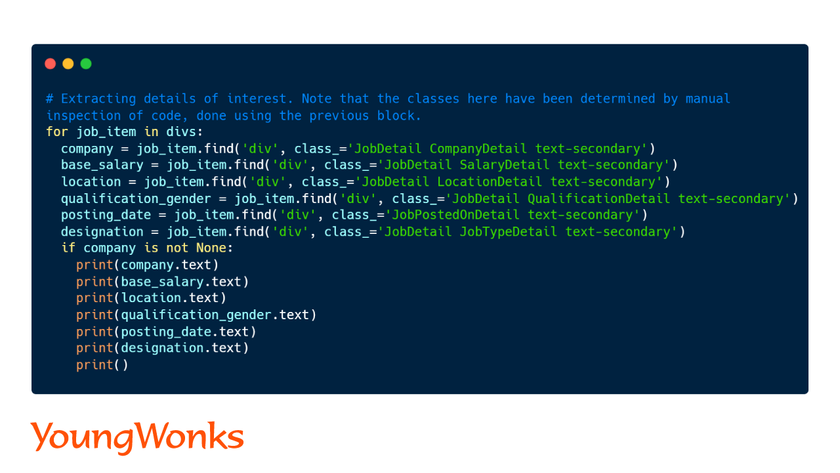
With the main class identified, getting to the specifics becomes as easy as diving deeper into the divs hierarchy. We determine and obtain the specific classes we’re after and store them in appropriate variables.
At this point, it is safe to assume that if one piece of information (company) is available, so will the rest.
Step IV - Creating the Scraper:
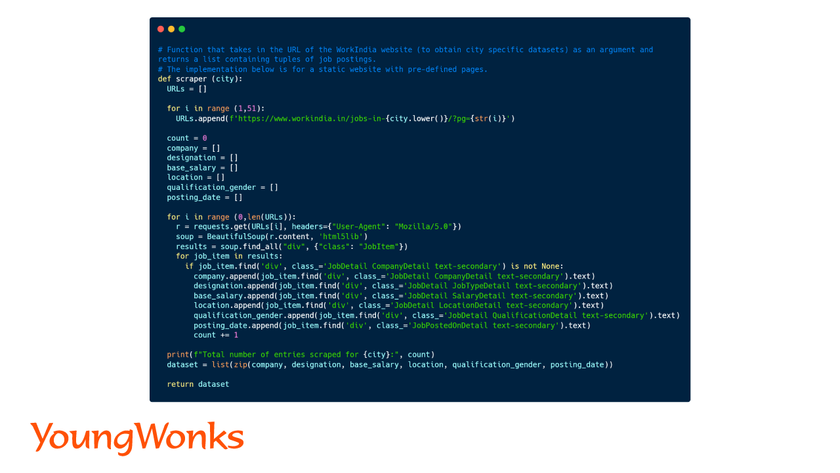
With all pieces of the puzzle at the ready, we create a function that takes in the target city as an argument, uses it to create the city-specific URL, and generates a list of URLs corresponding to the 50 pages of entries.
Looping through each URL, we repeat the process described in the testing steps to, instead of printing, append the obtained information into appropriately named lists.
With the lists and the extracted data now ready, the dataset is generated by using zip method to combine each entry in one list with the corresponding entry in the other lists to create what would be a row in the final dataset.
Step V - Generating the Dataset:
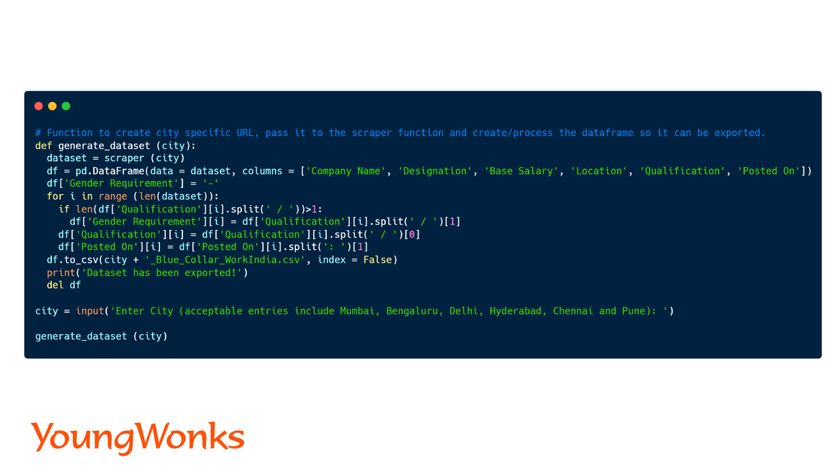
With the dataset handy (obtained using the scraper function and the scraped data), we use Pandas to create a pandas dataframe.
Since the dataset has the gender requirement and educational qualifications clubbed, we split them to create two different columns. Additionally, the substring 'Posted on: ' is removed from the 'Posted On' column.
The modified DataFrame is then converted into a .csv file, ready for data analysis. We can alternatively also convert it into a json file.
Step VI (Miscellaneous) - Scraping a Dynamically Reloading Website:
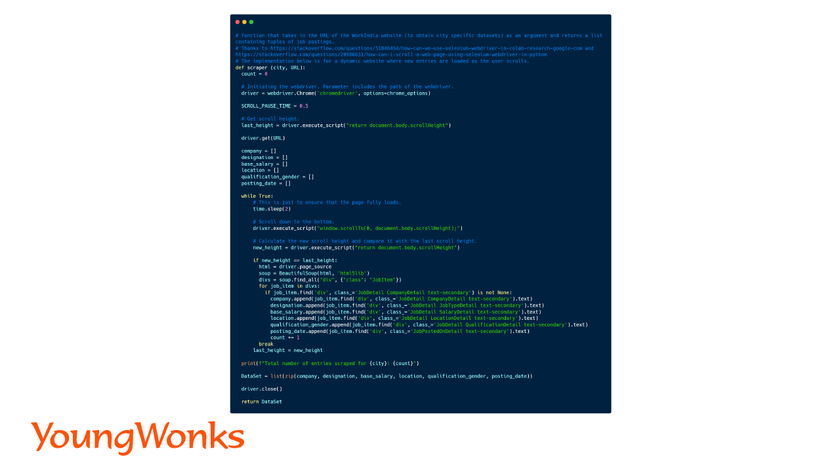
While our target website has all the data divided between pages, some websites load in more data as the user scrolls. In order to obtain all the available data, all we'll have to do is scroll down until the maximum depth is reached, at which point we scrape the entire website in one go.
The scraper here obtains the current height of the website, scrolls to the end (using Selenium), and compares the current height with the previous. If these happen to be the same, it means we have scrolled down to the end (thanks to the third post in the references).
Conclusion
I've said this before, and I'll say it again, data excites me. I see the potential to ascertain relationships and discover insights that can help show the way forward. When a niche dataset is then explored in this way, the potential is boundless.
What's more, we have an infinite source: the internet. The internet is a beautiful thing. It is a labyrinth that has all the information we need. Any tool that helps us make sense of this vast labyrinth is power unimaginable. And with automation, there isn’t anything we can keep track of.
If you've come this far, you have my sincerest gratitude. I hope this helps you obtain the dataset you need for your niche.
References
Enhance Your Coding Skills with YoungWonks
For those looking to broaden their understanding of web development and scraping technology, YoungWonks offers a comprehensive curriculum designed specifically for young learners. Our Coding Classes for Kids inspire students to dive into the world of technology and develop essential programming skills from an early age. For enthusiasts keen on mastering a versatile and widely-used programming language, our Python Coding Classes for Kids provide a solid foundation in Python, including its use in web scraping projects. Furthermore, students aspiring to become well-rounded developers can benefit from our Full Stack Web Development Classes, which cover both front-end and back-end technologies. At YoungWonks, we equip students with the tools and knowledge they need to turn their creative ideas into reality.
*Contributors: Written by Shravan Sridhar; Lead image by Shivendra Singh
